
Recently there has been shift in the way we organize code and do releases in one of our Ruby on Rails web projects. Previously, when we were introducing new major feature, we were going with pretty standard git-flow.
How do we use git-flow?
When using git flow, we usually work on feature branches (i.e. feature/1234-super-cool-stuff), and start them based on master branch. After work on given feature branch is completed, it gets merged back into master. This triggers automatic build on our CI server. Whenever CI server reports a green build on master, it automatically deploys the code to our staging server. The story is then tested on staging, and accepted/rejected. The whole process reiterates until all stories of current epic feature are tested and accepted.
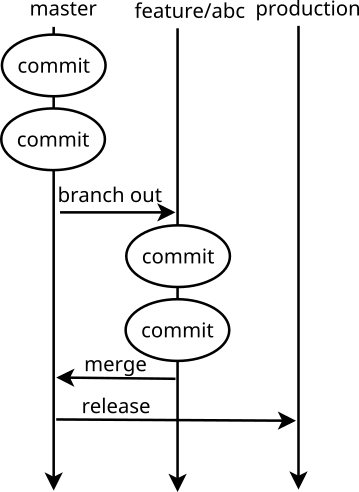
At this point, we are ready to release to production. This is done by merging master branch into production branch and triggering automatic deployment to production server. This happens behind the scenes as we use git flow release.
What’s wrong with git-flow?
Git-flow works great if we are developing one major feature at a time. Usually, however, we are developing a few major features simultaneously. The features are deployed to staging independently of each other, but when we want to release to production - we have to wait for the moment when all features are completed, deployed, and tested on our staging server (and master branch).
The client did not want that, and wanted to see ready to use features on production server as soon as we had them done. This was a problem we tried to fix:
We started maintaining a bunch of feature toggles. New features would be toggled off at first, so we could deploy to production without waiting for completion of those. This proved to be quite difficult in real life, and we ended up doing a lot of maintenance work. The features usually have dependencies that need to be turned on/off in order for the system to work correctly. We also ended up with having two versions of code chosen dynamically at runtime. This means more if-clauses, and also unnecessarily large codebase. After some time, we had to do regular clean ups of production code from previously used feature toggles. This process was quite error-prone as well.
New git branching model
A few months ago we came up with new way of organizing and deploying our Ruby code. At this stage of project life, we have to do hotfixes quite often anyway, so we decided to develop application mainly through hotfixes. Whether it’s a bug fix, or a new feature, we work on it by starting a branch based on production branch. To test it, we still merge it into master and deploy to staging server. If it passes quality check there, we can merge this branch back into production. The code then gets released to production server, without worrying about other - not yet finished features.
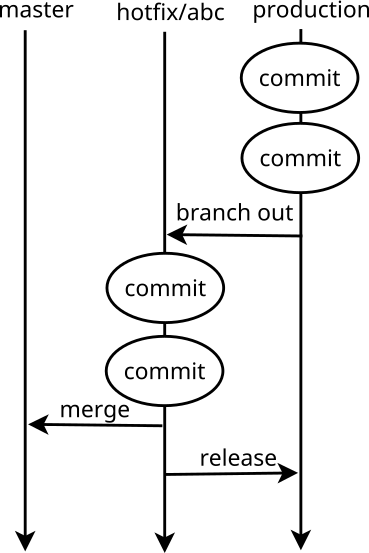
Bigger features, that consist of bunch of related stories, are kept on longer-living hotfix branches. We merge them a few times into master before they go to production. In unfinished state, however, they can be merged only on master.
The hotfix by default flow, allows us to deploy new features to production multiple times a day. This also results in quicker feedback from production users, who get to use new features on a daily basis. We noticed that, when we do a large release, bugs get overlooked more often too. Smaller feature, deployed to production takes less time to manually check for bugs than a large release of unrelated features.
One issue we stumbled upon, while testing this approach, were unwanted commits in pull requests on github. This happens because branches are merged separately to master and production. These two branches will differ in merge commits, which then can clutter pull request if we compare a branch based on production with master. Solution for this is to regularly merge production to master.
Summary
After four months we can say there are quite a few advantages of such approach. First of all, smaller chunks of code are deployed to production each time. This makes the releases less intimidating. Moreover, frequent releases let us get feedback from end users faster so we can respond to it better and faster.
As all rules, we occasionally decide to break our new git flow too. This happens, if we have a pile of related features, that really have to be deployed to production at the same time. In such cases, we do a sprint or two sprints where we revert to normal git-flow.

Post by Marcin Nieborak
Marcin joined our team in 2013. He specializes in Ruby, JavaScript and Elixir.