
Brave new world?
While ago I started my journey with Elixir. Learning the language was fun (I probably still have a few bits about OTP to catch up on, however). I pushed some simple commits to Elixir itself, made some bug fixes to Ecto. And then I figured I’m ready to learn how to use Phoenix, the web app framework similar to Rails.
When I was working on a simple app, I generated some scaffold, then wrote some controllers of my own, started talking to database using Ecto models in controllers… and then it hit me. I know where this leads. This way of building apps seemed appropriate for basic CRUD type of things, but what if I need to include user permissions? What if I need to have different validations for my users, and different registration flows depending on what role they have been invited to on the platform? This would be the same mess as following the Rails way in that case.
I started thinking about the ridiculously reliable and stable app we delivered for the British client a while ago. It is an intranet type of system for a corporation, with multiple levels of managers/employees, that can access different folders and files, upload payslips, review performance of supervised co-workers etc. What made it so good? We haven’t received a single bug report from the client during the two years it is live. I checked out the repository (no, I did not have need to keep it on my laptop otherwise - there are no bugs!) and looked around.
Internal API
Internal API. That’s the name we came up with. Since then we used the pattern multiple times, not even calling it that again. The workflow we employed when building the app was slightly different than standard TDD loop. We used test-first approach, but our test-fail-implement-repeat loop had an extra step:
- Write top-level integration test for feature from perspective of user (Capybara/browser test)
- Write high-level functional test for internal API of the application
- Write unit test cases for lower-level abstractions
- Implement the classes/methods/functions described in step 3
- Implement internal API of application (step 2)
- Implement Rails controllers/views etc. so that browser tests pass (step 1)
There’s plenty of steps, and having 100% test coverage definitely helped to make the app super reliable, but I think the secret was somewhere else.
Quite by accident, we have separated our application from Rails framework. Think about it, by having internal API, having it well defined and tested, we are using the framework merely as a means of passing the data to our application, sending it back and displaying in pretty form. This helped to make the updates go smooth between Rails releases, and I am sure it was a deciding factor to make the app so successful and reliable.
Layers
Let’s have a look on how we separate internal API from the framework and surrounding libraries. As about any problem in computing, you’ll need extra layer of abstraction ;).
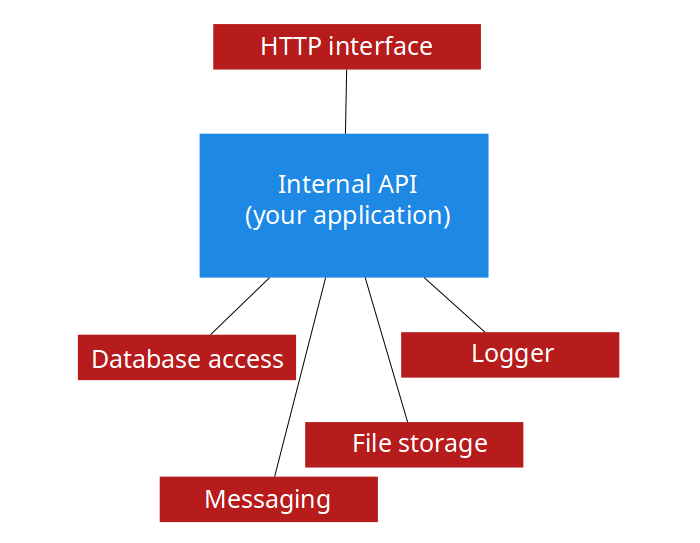
In simplest apps, there is only one interface accessing our internal API. If this is the case, you might consider more traditional approach and integrate more tightly with HTTP layer of the framework to cut some development time and have less code. But there is a price you’ll have to pay if your application gets additional interfaces, and it usually does. Think about interface as a layer sitting between events such as user actions, cron jobs, bash scripts etc., and your application. The role of the interface layer is to feed internal API with data, get different data back and present back to user, script, database and so on.
In most cases I saw, there were at least two, but often 3 or 4 interfaces for more complicated applications:
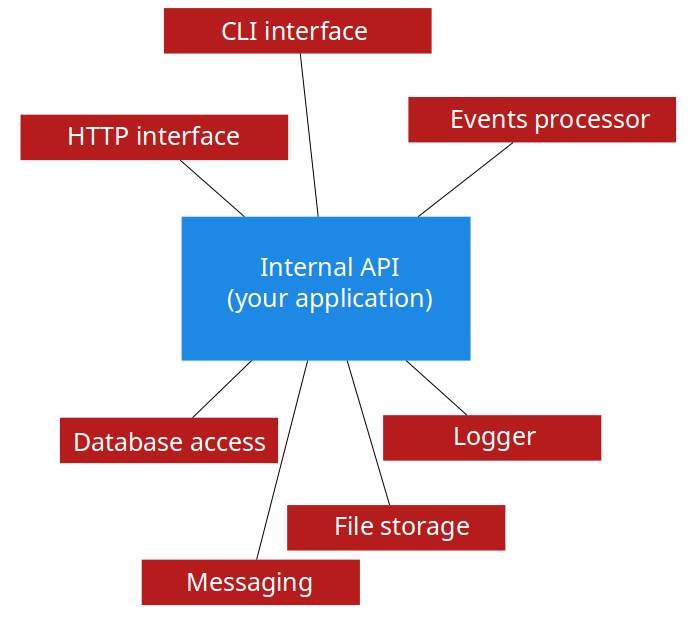
Let’s have a look at those diagrams from the perspective of user interacting with the application. The requests come from the top, pass through one of the interfaces, reach internal API. This layer performs some operations and returns back data to the user.
You can think of internal API as a black box sort of module, that is loosely coupled with the rest of the system you are building.
Internal API layer can, and usually does, exploit other parts of your framework or libraries. It could talk to the database using ActiveRecord (or Sequel), send e-mails using SMTP (or Mandrill), save files in local filesystem (or S3). The “or” part in the previous sentence is important. By making these parts of framework private to your internal API, you can think of swapping them around with different ones as you need it, without a need to change single line of code in your Rails controllers.
The important thing to note is that, in order to keep the system loosely coupled, the bottom layers (used privately by your internal API) do not leak to the top layers. This means your ActiveRecord models should not appear in the controllers directly, or be referenced by the Rake tasks. Instead, those layers should call appropriate methods in your internal API layer, that abstracts what is happening below.
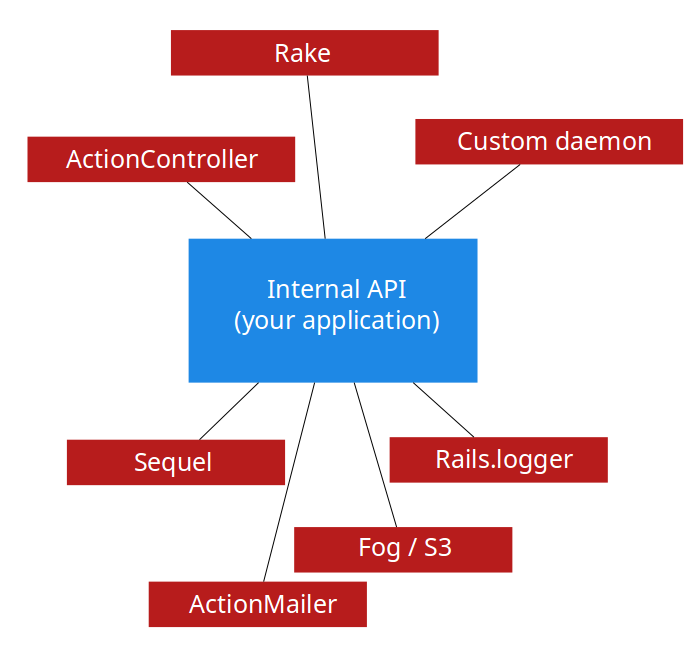
Breaking the rules
If you really do want to leak, say your ActiveRecord models to controllers and views, the best approach would be at least hide it’s class name and never reference it directly in the controller. Make your code look like:
app.reports.find(3)instead of
Report.where(creator_id: current_user.id).find(3)
This way you will be able to replace your model with something that acts
and quacks like one, but is not (think Virtus.model for example). No
one said your internal API cannot be identical in some places to what
the framework provides. I find the ActiveModel, and especially it’s
validations, useful. I tend to move them away from my ORM to form
objects, however.
The app object
I found it useful if the internal API I am building, has a common entry point. I call it the app object, because that’s the name I am giving for the variable holding a reference to it.
app object is a dispatch point to a tree-like structure of other
objects, that together provide public interface to your internal API
used by controllers or Rake tasks.
Most common pattern that I observed, is to instantiate the app object
with id of user. I often do it even in before_filter in Rails apps:
class ApplicationController < ActionController::Base
attr_reader :app
helper_method :app
before_filter :setup_app
private
def setup_app
@app = MyShinyApp.new(session[:user_id])
end
end
The app object acts as a gateway to parts of the API accessible to the
given user. For example, we can access the list of reports user has
access to with:
app.reports.listor validate a report and save it with:
app.reports.new_form(name: "my first report")
if app.reports.new_form.valid?
app.reports.new_form.save
else
...
end
The key thing here is that you can instantiate parts of the API to
restrict access to certain data only. app.reports.list will have
different filters depending on who is the user accessing the API
(remember, we passed user_id to the app when we instantiated it!).
This can be implemented by instantiating app.reports.list as a object
of different class, for different types of users. It might even make
sense to use some class-based inheritance here to provide common
interface for all types of report lists. Use design patters such as
template method to DRY-up your code.
Every user deserves custom API
The other technique which I am found of, is to not only provide
API that is aware of users’ restricted access to data, but that
restricts user access to certain functions. For users who have read-only
access to the list of reports, we simply instantiate app.reports using
a factory that returns the app.reports object that does not even
implementnew_form interface for creating and saving forms.
We can be even smarter, and in cases of attempting to access undefined / unavailable methods, raise custom exception. Let it crash as they say in Erlang community. The exception can be caught in the interface layer (or left to crash the system) to display error message to the naughty user.
# for administrator
app.reports.new_form(name: "my first form")
=> MyShinyApp::Reports::NewForm(...)
# for contractor
app.reports.new_form(name: "my first form")
=> raises MyShinyApp::AccessForbidden exceptionGive your code a structure on the filesystem
Unless you are writing Smalltalk, you need to store the code in files
on the disk. The Rails way is to have flat structure of classes and
modules in app/models, or app/services. This is okay if you have
little number of classes you use. I found, however, that people who try
to extract their logic to service objects without using the app object
pattern, could clutter their app/services (or similar) directory quite
badly.
Instead of having classes named ReporsListForAdministrators stored in
app/services, I like to have it called
‘MyShinyApp::Reports::ListForAdministrators’ and saved in
app/services/my_shiny_app/reports/list_for_administrators.rb. You can
tweak those paths to make them shorter by playing with Rails autoload
paths quite easily. The point is to save related classes grouped in
directories, and namespace them in modules often corresponding to the
tree-like structure of your internal API.
How is that making building additional interfaces easier?
Let’s think about advantages for building additional interfaces. Suppose your application needs a way to create new reports when user sends e-mail to it. You can write an interface layer that would sit between your mail server and the application:
while (form_data, user_id = read_from_next_received_email)
app = MyShinyApp.new(user_id)
app.reports.new_form(form_data)
if app.reports.new_form.valid?
....
else
email_user_form_errors(app.reports.new_form, user_id)
end
endWe build different interface to access our internal API but the API itself hasn’t changed. We did not have to access database models directly, and changes the user makes using email interface would have the same results (and side-effects) as the ones performed from the HTTP interface. If you had custom logging, notifications/alerts built into your internal API, they would be called the executed when calling API from both interfaces equally.
Test your internal API, test your interface
Having a clear layer of internal API, greatly improves your testing abilities. You can write functional black-box style tests for it easily. Those tests will run faster than Capybara/browser based ones, and you are able to test more edge case scenarios.
Testing your interface can be limited to making sure the interface works okay and passes the data back and forth to your internal API as expected.
One or multiple APIs?
If you build a big app, you might want to separate the APIs. For
example, your administrator users would use different set of features
than normal users. You can achieve that by instantiating different base
app object in different parts of the application. Since our components
are loosely based, I do not think there is anything wrong in re-using
the same ORM models in the internal APIs if you need it, and you can
make the behavior of them as similar or as different as you want.
The framework is your friend, but not the closest one
Think about your framework as something useful, something that can bring the value to your application, but do not integrate with it too tightly. This gives you the freedom to upgrade it, or even replace it in whole or parts in the future as you need it. You might even start to like it.
Now I just need to figure out a good way to apply this pattern in functional environments such as Phoenix…

Post by Hubert Łępicki
Hubert is partner at AmberBit. Rails, Elixir and functional programming are his areas of expertise.